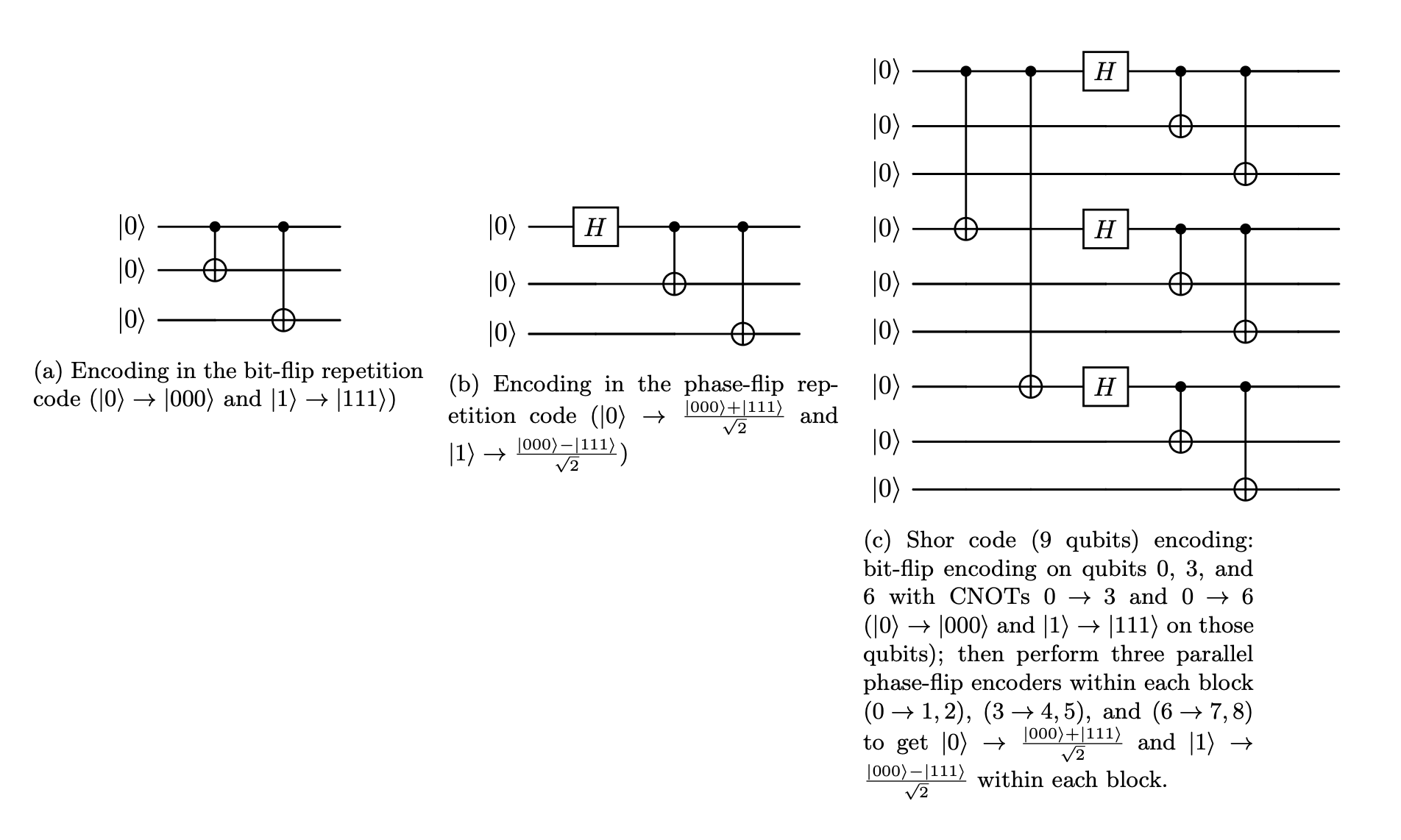
Combining bit-flip and phase-flip repetition codes: Shor’s 9-qubit code#
So far, we have seen how to encode qubits to protect from bit-flip and phase-flip errors, but only one of these two kinds of errors at a time. The Shor code, Peter Shor in 1995 [1], was the first quantum error-correcting code that could protect against both bit-flip and phase-flip errors. It achieves this through a clever technique called concatenation – essentially nesting one code inside another.
Here, we build the Shor code from scratch, and simulate the logical error probability of the Shor code for various physical error probabilities.
Encoding procedure#
The Shor code combines the encoding schemes of both repetition codes that we’ve seen so far using 9 physical qubits to encode 1 logical qubit.
First, encode against bit-flip errors (like the 3-qubit bit-flip code), by encoding \(\vert0\rangle \rightarrow \vert000\rangle\) and \(\vert1\rangle \rightarrow \vert111\rangle\).
Then, encode each qubit within the 3 blocks against phase-flip errors (like in the 3-qubit phase-flip code), by encoding \(\vert0\rangle \rightarrow \frac{\vert000\rangle + \vert111\rangle}{\sqrt{2}}\) and \(\vert1\rangle \rightarrow \frac{\vert000\rangle - \vert111\rangle}{\sqrt{2}}\) within each block.
This gives us 3 blocks of 3 qubits, for a total of 3 × 3 = 9 physical qubits which will serve as the data qubits.
The logical states are then
and
and the logical superposition states follow as usual:
and
encoder = create_shor_encoder(block_size = 3)
print(encoder)
0: ───@───@───H───@───@───
│ │ │ │
1: ───┼───┼───────X───┼───
│ │ │
2: ───┼───┼───────────X───
│ │
3: ───X───┼───H───@───@───
│ │ │
4: ───────┼───────X───┼───
│ │
5: ───────┼───────────X───
│
6: ───────X───H───@───@───
│ │
7: ───────────────X───┼───
│
8: ───────────────────X───
Extracting syndromes#
As before, we will use syndrome qubits to extract syndromes. Since there are 9 data qubits, we will need to do 8 pairwise parity checks and therefore require 8 additional syndrome qubits, for a total of 17 physical qubits. These 8 pairwise parity checks are composed of two kinds: 6 within-block parity checks to ensure consistency within each block, and 2 block-pair-wise parity checks to ensure consistency across the 3 blocks.
Parity checks within blocks#
Within each block, we will run \(Z_iZ_{i+1}\) parity checks to ensure bitwise consistency within that block, similar to bit-flip repetition codes. Since there are 3 blocks in total, each of which will need 2 such parity checks, we will need a total of 6 syndrome qubits to do this work.
bitflip_syndrome_meas = get_shor_bitflip_syndrome_measurement(block_size = 3)
print(bitflip_syndrome_meas)
0: ────@───────────────I───────────────────I───────────────────I───────────────────────
│
1: ────┼───@───@───────I───────────────────I───────────────────I───────────────────────
│ │ │
2: ────┼───┼───┼───@───I───────────────────I───────────────────I───────────────────────
│ │ │ │
3: ────┼───┼───┼───┼───I───@───────────────I───────────────────I───────────────────────
│ │ │ │ │
4: ────┼───┼───┼───┼───I───┼───@───@───────I───────────────────I───────────────────────
│ │ │ │ │ │ │
5: ────┼───┼───┼───┼───I───┼───┼───┼───@───I───────────────────I───────────────────────
│ │ │ │ │ │ │ │
6: ────┼───┼───┼───┼───I───┼───┼───┼───┼───I───@───────────────I───────────────────────
│ │ │ │ │ │ │ │ │
7: ────┼───┼───┼───┼───I───┼───┼───┼───┼───I───┼───@───@───────I───────────────────────
│ │ │ │ │ │ │ │ │ │ │
8: ────┼───┼───┼───┼───I───┼───┼───┼───┼───I───┼───┼───┼───@───I───────────────────────
│ │ │ │ │ │ │ │ │ │ │ │
9: ────X───X───┼───┼───────┼───┼───┼───┼───────┼───┼───┼───┼───M('bitflip-syndrome')───
│ │ │ │ │ │ │ │ │ │ │
10: ───────────X───X───────┼───┼───┼───┼───────┼───┼───┼───┼───M───────────────────────
│ │ │ │ │ │ │ │ │
11: ───────────────────────X───X───┼───┼───────┼───┼───┼───┼───M───────────────────────
│ │ │ │ │ │ │
12: ───────────────────────────────X───X───────┼───┼───┼───┼───M───────────────────────
│ │ │ │ │
13: ───────────────────────────────────────────X───X───┼───┼───M───────────────────────
│ │ │
14: ───────────────────────────────────────────────────X───X───M───────────────────────
Parity checks across blocks#
We will also run parity checks to ensure phase consistency across all 3 blocks. To do so, we run \(X_iX_{i+1}\) parity checks across blocks. Note that when \(Z\) errors occur within each block, only an odd number of such errors causes a phase consistency across blocks (since \(Z_i\vert111\rangle = -\vert111\rangle\) and \(-Z_j\vert111\rangle = \vert111\rangle\) for any \(i\) and \(j\) within a block). One parity check will measure the phase consistency between blocks 0 and 1 (by running \(X_0X_1X_2X_3X_4X_5\)), and another will measure the phase consistency between blocks 0 and 2 (by running \(X_0X_1X_2X_6X_7X_8\)). If two blocks are inconsistent but we know that they are, we can simply apply a single \(Z\) gate in one of the blocks to bring them back to consistency and avoid a logical error.
Note that there are two methods for running an \(X_iX_j\) parity check (see Dan Browne’s lecture notes, section 1.3.9. In one method, we initialize the syndrome qubits in the Hadamard basis, run controlled-\(X\) gates from the syndrome qubits to the data qubits, and then measure the syndrome in the Hadamard basis. The circuit identity \(HZH = X\) can be used to transform this method into the second: apply \(H\) gates to all data qubits, and run controlled-\(X\) gates from the data qubits to the syndrome qubits.
We will use the latter method below.
phaseflip_syndrome_meas = get_shor_phaseflip_syndrome_measurement(block_size = 3)
print(phaseflip_syndrome_meas)
┌──┐ ┌──┐
0: ────H───@────@────────────────────────────────────────────────────H─────────────────────────
│ │
1: ────H───┼────┼@─────@─────────────────────────────────────────────H─────────────────────────
│ ││ │
2: ────H───┼────┼┼─────┼@────@───────────────────────────────────────H─────────────────────────
│ ││ ││ │
3: ────H───┼────┼┼─────┼┼────┼───────@───────────────────────────────H─────────────────────────
│ ││ ││ │ │
4: ────H───┼────┼┼─────┼┼────┼───────┼───@───────────────────────────H─────────────────────────
│ ││ ││ │ │ │
5: ────H───┼────┼┼─────┼┼────┼───────┼───┼───@───────────────────────H─────────────────────────
│ ││ ││ │ │ │ │
6: ────H───┼────┼┼─────┼┼────┼───────┼───┼───┼───────@───────────────H─────────────────────────
│ ││ ││ │ │ │ │ │
7: ────H───┼────┼┼─────┼┼────┼───────┼───┼───┼───────┼───@───────────H─────────────────────────
│ ││ ││ │ │ │ │ │ │
8: ────H───┼────┼┼─────┼┼────┼───────┼───┼───┼───────┼───┼───@───────H─────────────────────────
│ ││ ││ │ │ │ │ │ │ │
15: ───────X────┼X─────┼X────┼───I───X───X───X───I───┼───┼───┼───I───M('phaseflip-syndrome')───
│ │ │ │ │ │ │
16: ────────────X──────X─────X───I───────────────I───X───X───X───I───M─────────────────────────
└──┘ └──┘
Creating the initial state#
We will use standard rotations to initialize the state of the qubit that is protected by the Shor code. An \(X\) gate will flip it from \(\vert0\rangle\) to \(\vert1\rangle\), an \(H\) gate will flip \(\vert0\rangle\) to \(\vert+\rangle\), and a combination of both will flip \(\vert0\rangle\) to \(\vert-\rangle\) (\(\vert-\rangle = ZH\vert0\rangle\)).
create_initial_state('+')
0: ───H───
Applying noise#
As we have seen in the previous chapter on phase-flip repetition codes, we will need to track the errors that we have applied in order to run simulations of the performance of the error-correcting code. The function below applies noise to the relevant data qubits, and then reports which ones it applied.
def create_noise_circuit(p = 0.1, block_size = 3, error_gate = cirq.Z):
def flip(p):
return 1 if random.random() < p else 0
noise_circuit = cirq.Circuit()
data_qubits = cirq.LineQubit.range(block_size * block_size)
has_error = [flip(p) for _ in range(len(data_qubits))]
error_indices = [i for i, x in enumerate(has_error) if x == 1]
errors = []
for error_index in error_indices:
noise_circuit.append(error_gate(data_qubits[error_index]))
errors.append(error_gate)
return noise_circuit, [error_indices, errors]
Putting it all together#
We can now combine all the pieces above into a full run of the Shor code. Once we construct the circuit to encode the state of one qubit into the 9 qubits of the Shor code, apply noise, and run our syndrome checks, we will need to decode the syndrome checks and determine whether a logical error has occurred.
A logical error can happen in two ways:
If a single \(Z\) errors happens within a block, then we will be able to determine the location of that block through the phase consistency checks described above. However, if two \(Z\) errors happen in two different blocks, then our phase consistency’s majority vote will fail to identify where these errors occurred, leading to a logical error.
If a single \(X\) error occurs within a block, then we will be able to determine its location through the within-block bitwise parity checks described above. However, if two \(X\) errors occur within the same block, these within-block parity checks will not be able to identify the correct location since the majority vote within the block fails to identify the flipped data qubit and a logical error occurs.
As before, we write a loop to go through several values of physical error probabilities and test the performance of the error-correcting code to those errors.
starting_state = '0'
error_gate = cirq.Z
block_sizes = [3]
physical_errors = np.logspace(-3, 0, 10) # 10^-3 = 0.001 to 10^0 = 1 in 10 steps
simulator = cirq.CliffordSimulator()
all_logical_errors = get_logical_error_probability_simulated(block_sizes, physical_errors,
n_shots = 50000, simulator = simulator,
starting_state = starting_state, error_gate = error_gate)
Simulating block-size-3 Shor code circuits
100%|██████████████████████████████████████████████████████████████████████████████| 10/10 [16:21<00:00, 98.12s/it]
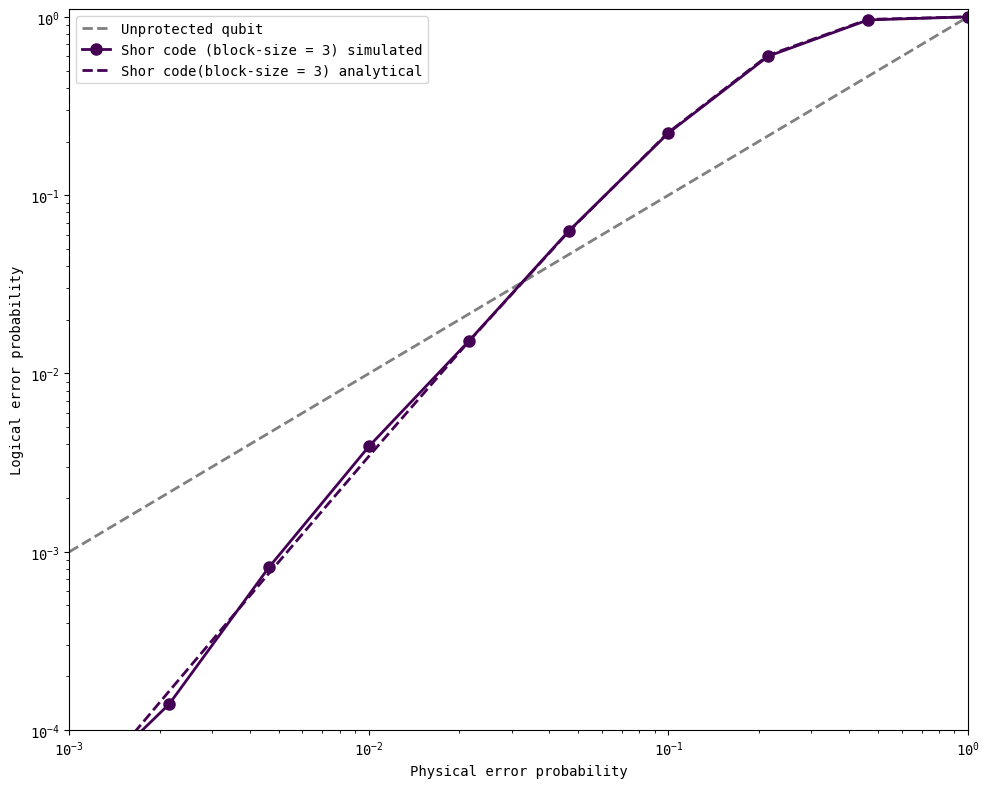
Now, we can derive an analytical expression for the logical error probability using the same arguments that we have previously seen for repetition codes. We will consider the case of \(Z\) errors where the initial state is \(\vert+\rangle_L\) for simplicity, for the Shor code where the size of each block is \(\text{blocksize}\). There are 9 (\(\text{blocksize}^2\)) data qubits that can experience a \(Z\) error. If more than one \(Z\) flip occurs, then we will be unable to detect where it happened with our 2 parity checks that compare the blocks.
There are \(\binom{9}{0} = 1\) cases where no \(Z\) flips occur (with probability \(\left(1-p\right)^9\)), and \(\binom{9}{1} = 9\) cases where one \(Z\) flip occurs (with probability \(p\left(1-p\right)^8\) each). Any other case leads to a logical error. Then, the probabilty of success is
This is exactly the same as our previously derived expression
where we replace \(d\) by \(\text{blocksize}^2\) within the sum, since that represents the total number of qubits used in the encoding procedure that could experience errors, but keep the sum running up to at most \(\lfloor d/2\rfloor\) since that is the number of flips that will cause a logical error.
plot_logical_error_probabilities( block_sizes, physical_errors, all_logical_errors, all_analytical_errors, ylim = [1e-4, 1.1])
Faster code performance simulations#
In order to test the performance of the Shor code at low errors, we will need to run millions of shots. However, the simulation time above is prohibitively high. To get around this problem, we will use the sampling techniques covered in the previous chapter on running faster circuit simulations. We will first adapt the code above to generate a syndrome table that collects all possible error locations and flags to indicate whether or not they lead to a logical error. Then, we will sample from this syndrome table repeatedly instead of running circuits. The code below samples from the syndrome table using the GPU on the author’s laptop. If this is not available for you, the speedup from using a syndrome table should still be significant.
starting_state = '0'
error_gate = cirq.Z
block_sizes = [3]
physical_errors = np.logspace(-5, 0, 10) # 10^-5 to 10^0 in 10 logsteps
starting_state = '0'
error_gate = cirq.X
block_sizes = [3]
physical_errors = np.logspace(-5, 0, 10) # 10^-5 to 10^0 in 10 logsteps
starting_state = '+'
error_gate = cirq.Z
block_sizes = [3]
physical_errors = np.logspace(-5, 0, 10) # 10^-5 to 10^0 in 10 logsteps
starting_state = '+'
error_gate = cirq.X
block_sizes = [3]
physical_errors = np.logspace(-5, 0, 10) # 10^-5 to 10^0 in 10 logsteps
all_analytical_errors = get_logical_error_probability_analytical(block_sizes, physical_errors)
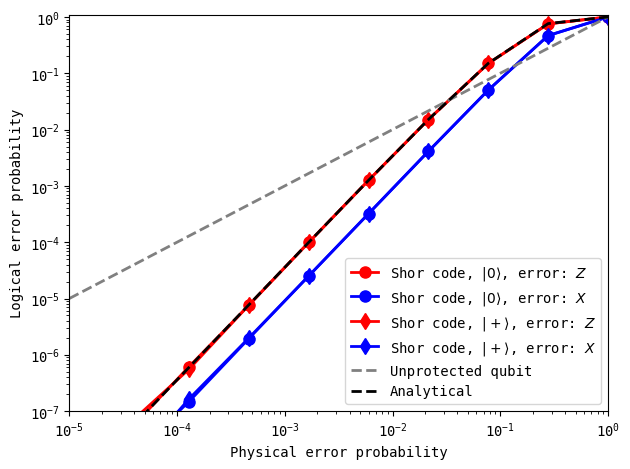
With faster simulations, we are now able to see that the Shor code can bring logical errors down significantly as the physical error probability lowers. Note that the Shor code is able to suppress both \(X\) and \(Z\) errors, independent of the starting state. One of the exercises below encourages you to consider why there is a \(\sim3\times\) gap between the case of \(X\) and \(Z\) errors – this gap does not depend on the starting state.
Exercises for the reader
Note that the logical error probabilities for \(Z\) errors and \(X\) errors are \(\sim3\)x apart in the above figure. Can you explain this difference? (Hint: consider the number of ways that logical errors can occur within blocks and between blocks).
Would increasing the block size in the Shor code achieve better results?
At what level of physical error probability does the Shor code outperform the bare unprotected qubit?
References#
P. W. Shor, Scheme for reducing decoherence in quantum computer memory. Phys. Rev. A 52, R2493 (1995). PRA article
Calderbank and Shor, Good error-correcting codes exist (1995). arXiv:quant-ph/9512032
Version History#
v0: Sep 12, 2025, github/@aasfaw
v1: Sep 12, 2025, github/@aasfaw readability improvements, syndrome check circuits image, faster simulations