Running faster circuit simulations#
So far, you have learned about bit-flip and phase-flip repetition codes. In the process, you have also seen how these error-correcting codes perform by simulating their behavior – to do this, you ran quantum circuits containing different amounts of errors, and observed how the codes perform under these settings.
For bit-flip repetition codes, we ran our quantum circuits with up to 1 million repetitions and were able to see logical error probabilities of order 1 in 1 million. You saw that running 1 million shots/repetitions took about a second. On the other hand, for phase-flip repetition codes, where we needed to create a new quantum circuit for each instance of the code with varying levels of noise, it took about 30 seconds to collect statistics by running 50,000 circuits at the smallest distance = 3. However, in order to test the performance of these error-correcting codes down to the 1 in 1 billion level, we will somehow need to run billions of circuits, which seems prohibitively expense.
The reason for the significant slowdown in the phase-flip setting is related to the need for tracking where we inserted errors – we needed to do this to determine when our decoded syndromes were successfully predictive of these locations. Because each circuit contains a different instance of noise on some subset of the data qubits, our general execution structure was
for each distance
for each physical qubit error level
for 50000 shots
create 1 random instance of the circuit, record where errors were inserted
run that circuit
decode the syndrome measurements
determine whether a logical error happened (decoded error locations ?= inserted error locations), if so add to count
In contrast, in the bit-flip case, our execution structure was
for each distance
for each physical qubit error level
create one instance of the circuit containing probabilistic error gates
run that circuit 1000000 times
decode the syndrome measurements
for each shot:
determine whether a logical error happened (decoded error locations ?= inserted error locations), if so add to count
Note that we are taking full advantage of the Clifford simulation capability of cirq when we run the same circuit 1 million times in the bit-flip case, but lose that benefit when we run 1 circuit each time in the phase-flip case and incur the overhead of running that circuit each time.
In this notebook, we will dramatically improve the execution speed of the phase-flip repetition code, reducing it from 30 seconds for 50,000 shots to 5 seconds for 10 billion shots. In the process, you will see some of the techniques that the standard tools of QEC employ to run these simulations quickly.
0. Starting point#
We will demonstrate a number of techniques for speeding up the simulations of the performance of our phase-flip repetition codes. These techniques are generally applicable, and are routinely used in quantum error correction research.
Our starting point is reproduced below, with just the necessary parts. Note that we have moved most of the functionality that we built for phase-flip repetition codes into a separate .py file that can be imported. We run it again to record the timing results.
logical_state = '+'; error_gate = cirq.Z
distances = [3]
physical_errors = np.logspace(-3, 0, 10)
n_shots = 50000
all_logical_errors = []
for distance in distances:
print(f"Running distance {distance}, phase-flip rep code, initialized as |{logical_state}>_L, error gate {error_gate}")
thisdistance_logicalerrors = []
for error_probability in tqdm(physical_errors):
logical_error_probability = get_logical_error_probability_for_rep_code(n_qubits = distance, error_probability = error_probability, n_shots = n_shots,
logical_state = logical_state, error_gate = error_gate
)
thisdistance_logicalerrors.append(logical_error_probability)
all_logical_errors.append(thisdistance_logicalerrors)
Running distance 3, phase-flip rep code, initialized as |+>_L, error gate Z
100%|████████████████████████████████████████████████████████████████████████████████| 10/10 [05:54<00:00, 35.43s/it]
As you can see, each physical error takes about 30 seconds to run with 50,000 shots at distance 3.
1. Reducing the number of quantum circuits that we need to run redundantly (800x speedup)#
Recall the structure of our execution for the phase-flip repetition code.
for each distance
for each physical qubit error probability
for n_shots=50000 shots
create 1 random instance of the circuit, record where errors were inserted
run that circuit
decode the syndrome measurements
determine whether a logical error happened (decoded error locations ?= inserted error locations), if so add to count
Note that we are running number of shots \(\times\) number of distances \(\times\) number of physical errors circuits.
Each random noisy instance of the circuit contains some combination of Pauli-\(Z\) gates on the data qubits. Since we know the number of data qubits (\(d\)), there are at most \(d\) different ways to place a single Pauli-\(Z\) gate, \(d-\)choose\(-2\) ways to place two Pauli-\(Z\) gates, and so on. More generally, there are a total of \(2^d\) different combinations of circuits. We can enumerate these by writing an array with \(d\) entries that are either 0 or 1, where 0 (1) signifies the absence (presence) of a \(Z\) gate, for a total of \(2^d\) possible such arrays.
Using this observation, we can replace our execution to the following:
### first, create the syndrome table by running circuits containing all possible error locations only once
for each d = distance
create all 2^d circuits with noise inserted at all possible combinations of qubits
run those 2^d circuits and measure the syndromes
decode the 2^d syndrome measurements
determine whether a logical error happened (decoded error locations ?= inserted error locations); save to syndrome table with decision for later lookup
### next, sample from the syndrome table
for each distance
for each physical qubit error probability
generate a matrix with (rows = n_shots, columns = distance); each row is an error pattern generated using the physical qubit error probability
look up each row in the syndrome table and determine if a logical error occurs
sum the number of times a logical error occurred, and divide by n_shots to get a probability
Note that we are now running only 2^d circuits. Since matrix manipulation can be done very quickly, the rest of the steps add very little execution time, and the speedup becomes significant. We implement this procedure below.
logical_state = '+'; error_gate = cirq.Z
distances = [3]
physical_errors = np.logspace(-3, 0, 10)
n_shots = 10_000_000
Running distance 3, phase-flip rep codes, initialized as |+>_L, error gate Z
Getting syndromes for all possible error locations in distance 3, |+>_L
Done getting syndromes for all possible error locations in distance 3, |+>_L
100%|████████████████████████████████████████████████████████████████████████████████| 10/10 [01:10<00:00, 7.02s/it]
As you can see, we have sped up our simulations significantly. What used to take 30 seconds for 50,000 shots at distance 3 now takes 7 seconds for 10,000,000 shots, an 800x speedup.
Chunking and batching to reduce memory usage#
Note that our current implementation of simulate_with_syndrome_table creates an array of size (n_shots, n_qubits). For 10 million shots, this may not matter much. But for simulations where the logical error probability is in the \(10^{-9}\) range, we will require about a billion shots. At that point, memory usage is significant. Try running the above example with 1 billion shots to see what happens! (Hint: it will take a prohibitively long time to get a datapoint).
We can solve this problem by generating error patterns for 100,000,000 shots at a time, and processing batches of 10,000 error patterns at a time by looking them up in the syndrome table.
### chunked and batched sampling from the syndrome table
for each distance
for each physical qubit error probability
n_chunks = total number of shots / memory limit
for each chunk:
n_batches = chunk size / batch size
for each batch:
generate a matrix with (rows = batch size, columns = distance); each row is an error pattern generated using the physical qubit error probability
look up each row in the syndrome table and determine if a logical error occurs
add to total logical error count if this specific row leads to logical errors
sum the number of times a logical error occurred, and divide by n_shots to get a probability
Note that chunking and processing in batches does not result in a speedup, but reduces the memory usage.
logical_state = '+'; error_gate = cirq.Z
distances = [3]
physical_errors = np.logspace(-3, 0, 10)
n_shots = 10_000_000
Running distance 3, phase-flip rep codes, |+>_L, error gate Z
Getting syndromes for all possible error locations in distance 3, |+>_L
Done getting syndromes for all possible error locations in distance 3, |+>_L
100%|████████████████████████████████████████████████████████████████████████████████| 10/10 [01:10<00:00, 7.03s/it]
2. Parallelizing execution of batches of circuits across CPUs (6000x speedup)#
Now that we have rearranged the execution of simulate_with_syndrome_table into chunks, with each chunk itself broken into smaller batches, we can parallelize the execution of those batches across several CPUs (and later on GPUs). This should give a speedup of the execution by a factor of the number of CPUs used, assuming that we are able to orchestrate and aggregate the results from each of those CPUs efficiently.
Thankfully, Python makes this easy with the use of the joblib library. To do this, we will first define a parallelized version of simulate_with_syndrome_table called simulate_with_syndrome_table_parallel which runs each batch across n_workers CPU threads.
Then, sampling from the syndrome table now looks like the following:
### chunked and batched sampling from the syndrome table
for each distance
for each physical qubit error probability
n_chunks = total number of shots / memory limit
for each chunk:
n_batches = chunk size / batch size
run single batches across multiple CPU threads:
generate a matrix with (rows = batch size, columns = distance); each row is an error pattern generated using the physical qubit error probability
look up each row in the syndrome table and determine if a logical error occurs
add to total logical error count if this specific row leads to logical errors
sum the number of times a logical error occurred, and divide by n_shots to get a probability
logical_state = '+'; error_gate = cirq.Z
distances = [3]
physical_errors = np.logspace(-3, 0, 10)
n_shots = 10_000_000
Running distance 3, phase-flip rep codes, |+>_L, error gate Z
Getting syndromes for all possible error locations in distance 3, |+>_L
Done getting syndromes for all possible error locations in distance 3, |+>_L
100%|████████████████████████████████████████████████████████████████████████████████| 10/10 [00:09<00:00, 1.05it/s]
As you can see, it now takes about 1 second for 10 million shots of a specific physical error probability at distance 3. This is another 6-7x speedup on top of the gains from using a syndrome table. You may notice that we have used n_workers = 8 above. The author’s laptop has 8 performance cores on an Apple MacBook Pro M2 Max, which motivated this choice. The resulting 6-7x speedup is quite close to the number of CPUs, and the remaining bottleneck is orchestration across these CPUs.
What used to take 30 seconds for 50000 shots at distance 3 now takes 1 second for 10,000,000 shots, a 6000x speedup.
3. Adding GPUs to the mix (1,000,000x speedup)#
GPUs are particularly well-suited for matrix operations. We can take full advantage of this by running the syndrome table sampling on GPUs. In this section, we focus our efforts on adapting the syndrome sampling procedure to run on the GPUs in an Apple MacBook Pro with Apple’s M2 Max processor, using Apple’s MLX library. However, the techniques used here are generally adaptable to other GPUs.
Recall that we created the syndrome table as a dictionary indexed by tuple(specific_error_locations). This tuple contains 1 where the qubits had errors, and 0 where they didn’t.
decoded_syndrome_table = {}
for specific_error_locations, syndromes, decoded_error_locations in zip(all_possible_error_locations, all_syndromes, all_decoded_error_locations):
is_logical_error = set(specific_error_locations) != set(decoded_error_locations)
decoded_syndrome_table[tuple(specific_error_locations)] = [syndromes, decoded_error_locations, is_logical_error]
To sample the syndrome table on a GPU, we will first convert this syndrome table into a GPU-friendly format. Then, we will run batches of size 100MB at a time on the GPU, until all shots are completed. This number is specific to the memory available on your computer – at distance 9, it requires approximately 9 bits x 100MB ≈ 0.9 GB of memory.
logical_state = '+'; error_gate = cirq.Z
distances = [3, 5, 7, 9]
physical_errors = np.logspace(-3, 0, 10)
n_shots = 10_000_000_000
Running distance 3, phase-flip rep codes, |+>_L, error gate Z
Getting syndromes for all possible error locations in distance 3, |+>_L
Done getting syndromes for all possible error locations in distance 3, |+>_L
100%|████████████████████████████████████████████████████████████████████████████████| 10/10 [00:56<00:00, 5.63s/it]
Running distance 5, phase-flip rep codes, |+>_L, error gate Z
Getting syndromes for all possible error locations in distance 5, |+>_L
Done getting syndromes for all possible error locations in distance 5, |+>_L
100%|████████████████████████████████████████████████████████████████████████████████| 10/10 [01:32<00:00, 9.28s/it]
Running distance 7, phase-flip rep codes, |+>_L, error gate Z
Getting syndromes for all possible error locations in distance 7, |+>_L
Done getting syndromes for all possible error locations in distance 7, |+>_L
100%|████████████████████████████████████████████████████████████████████████████████| 10/10 [02:07<00:00, 12.71s/it]
Running distance 9, phase-flip rep codes, |+>_L, error gate Z
Getting syndromes for all possible error locations in distance 9, |+>_L
Done getting syndromes for all possible error locations in distance 9, |+>_L
100%|████████████████████████████████████████████████████████████████████████████████| 10/10 [02:42<00:00, 16.28s/it]
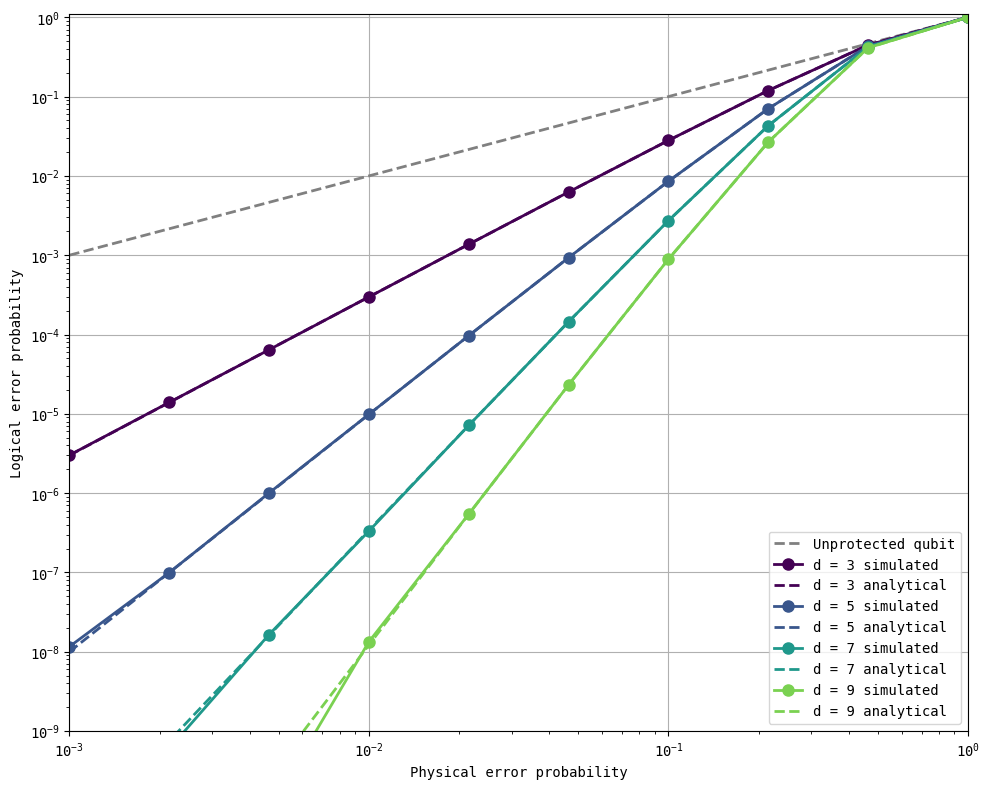
As you can see, it now takes about 5 seconds for 10 billion shots of a specific physical error probability at distance 3. This is another 200x speedup on top of the gains from using a syndrome table and parallelizing across CPU threads. What used to take 30 seconds for 50000 shots at distance 3 now takes 5 seconds for 10,000,000,000 shots, a 1,000,000x speedup.
The key benefit of being able to run 10B (\(10\times10^9\)) shots is that we can simulate the performance of our error-correcting codes down to logical errors of order \(\sim10^{-9}\), where the benefits of quantum error correction are expected to enable useful quantum algorithms.
all_analytical_errors = get_logical_error_probability_analytical(distances, physical_errors)
plot_logical_error_probabilities(distances, physical_errors, all_logical_errors, all_analytical_errors, ylim=[1e-9, 1.1])
4. Hints for further speedup#
So far, we have sampled all \(10\times10^9\) shots from the syndrome table. By reducing the number of circuit executions to just the number of circuits needed to prepare the syndrome table, and sampling from that table repeatedly without running circuits, we have achieved the speedups that we have seen so far.
To motivate additional speedups, it’s instructive to look at the generated error patterns that we are looking up in the syndrome table. Below, we demonstrate the error patterns for distance 7, with physical error probability 0.2, and 100 million shots.
show_error_pattern_distribution(n_qubits = 7, error_probability = 0.2, n_shots = 100_000_000)
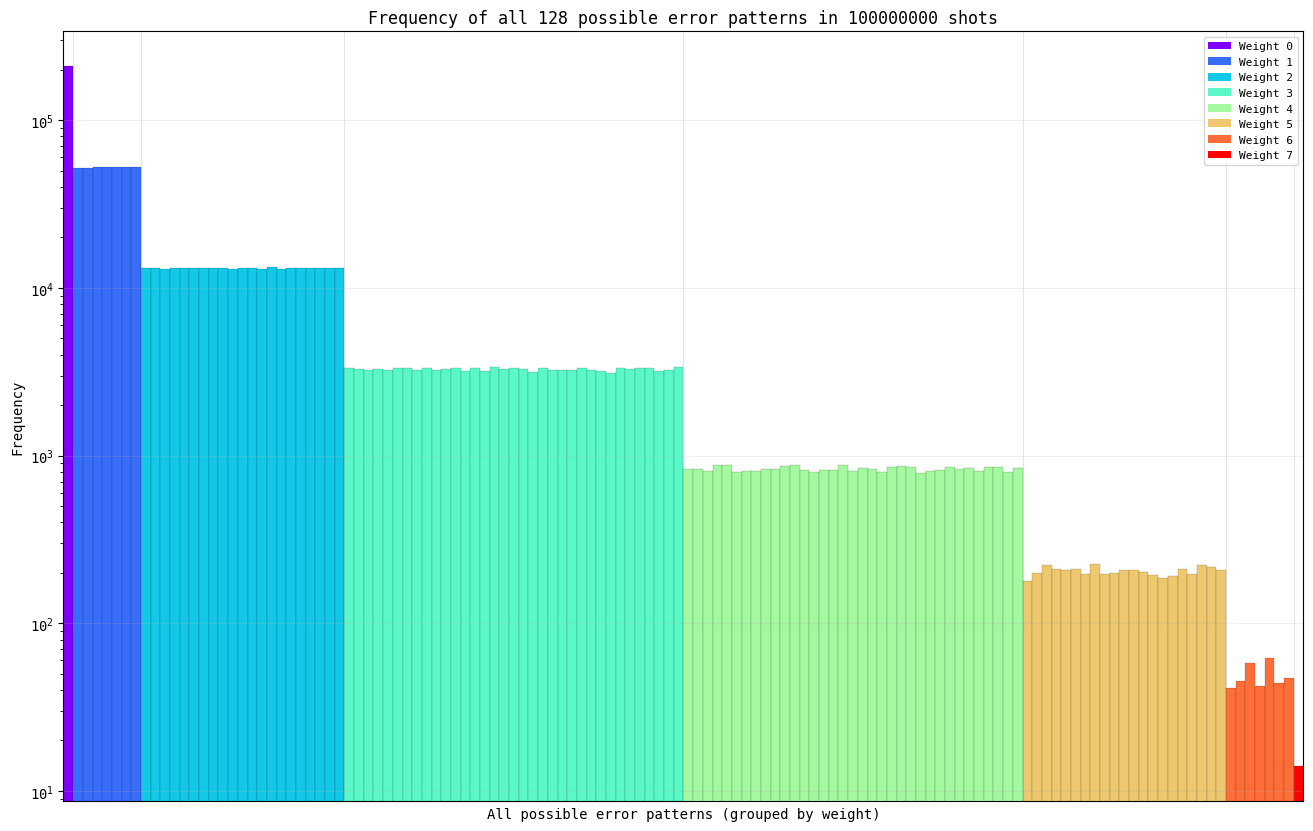
As you can see, there is only one way to have weight-0 errors (no errors on all qubits), and that occurs with a frequency of about 200,000 times out of a total of 100 million samples (0.2%), 7 different ways to have weight-1 errors (one error on each qubit at distance 7), each of which occurs about 50,000 times (0.05%), and so on.
So far, we have been sampling all error patterns (in the above example, we would have sampled all 10 million error patterns). But as you can see above, there is a significant amount of redundancy in doing so, and grouping should provide significant speedup if we can predetermine the weights of these groupings.
Can you take advantage of this observation to further reduce the simulation time? If so, as you can see above, there is an additional ~10000x to be gained. :)
Version History#
v0: Sep 7, 2025, github/@aasfaw
v1: Sep 13, 2025, github/@aasfaw readability improvements, 2B->10B GPU shots